






目次
1. Qwen3.5の概要
Qwen3.5は、中国のテクノロジー企業Alibaba Cloud(アリババクラウド)のQwenチームが開発・公開した大規模言語モデル(LLM)シリーズです。2026年初頭に段階的にリリースされ、モデルサイズと用途の幅広さで注目を集めています。
主な特徴
| 特徴 | 詳細 |
|---|---|
| マルチモーダル対応 | テキストだけでなく、画像入力にも対応(VLM) |
| 長文コンテキスト | 最大 262,144トークン(262K)のネイティブコンテキストウィンドウ |
| 多言語対応 | 201言語をサポート(日本語含む) |
| 推論モード | デフォルトで推論(Reasoning)機能を内蔵 |
| アーキテクチャ | Qwen-Nextアーキテクチャ(GDNレイヤー採用) |
| ライセンス | Apache 2.0(商用利用可) |
リリースの経緯
Qwen3.5は2026年にわたって3段階でリリースされました。
- 2026年2月16日 – フラッグシップモデル(397B-A17B MoE)公開
- 2026年2月24日 – ミディアムシリーズ(27B、35B-A3B、122B-A10B)公開
- 2026年3月2日 – スモールシリーズ(0.8B〜9B)公開
初期の大規模モデルから小型モデルまで段階的にリリースすることで、研究者から一般ユーザーまで幅広い層での活用を実現しています。
2. Ollamaの概要
Ollamaとは
Ollamaは、LLaMA・Qwen・DeepSeek・MistralなどのオープンソースLLMをローカル環境で簡単に実行できるオープンソースツールです。クラウドサービスを使わずに自社・自分のハードウェア上でAIモデルを動かすことができます。
主な利点:
- プライバシー保護:データが外部に送信されない
- オフライン動作:インターネット接続不要
- コスト削減:API課金が発生しない
- 簡単な操作:1コマンドでモデルの取得・実行が可能
2025年7月30日には、macOSおよびWindows向けのネイティブデスクトップアプリが正式リリースされ、さらに使いやすくなりました。
3. Qwen3.5 モデルサイズ一覧
Qwen3.5は用途や計算リソースに合わせて選べる豊富なモデルラインナップを提供しています。
スモールシリーズ(ローカル環境向け)
| モデル名 | パラメータ数 | 特徴 | 推奨用途 |
|---|---|---|---|
qwen3.5:0.8b | 0.8B(8億) | 超軽量、CPU動作可能 | 組み込みデバイス、低スペックPC |
qwen3.5:2b | 2B(20億) | 軽量、高速応答 | モバイル、エッジデバイス |
qwen3.5:4b | 4B(40億) | バランス型 | 一般的なPC、日常タスク |
qwen3.5:9b | 9B(90億) | 高品質、ローカル最適解 | ハイエンドPC、開発・研究 |
ミディアムシリーズ(高性能サーバー向け)
| モデル名 | パラメータ数 | アーキテクチャ | 特徴 |
|---|---|---|---|
qwen3.5:27b | 27B(270億) | Dense(密) | 高品質・低レイテンシ |
qwen3.5:35b-a3b | 35B総数 / 3B有効化 | MoE(混合エキスパート) | 35Bの知識を3Bの計算コストで利用 |
qwen3.5:122b-a10b | 122B総数 / 10B有効化 | MoE | フロンティア級の性能 |
フラッグシップシリーズ(クラウド・大規模向け)
| モデル名 | パラメータ数 | アーキテクチャ | 特徴 |
|---|---|---|---|
qwen3.5:397b-a17b | 397B総数 / 17B有効化 | MoE | 最上位モデル、GPT-4クラスの性能 |
MoE(Mixture of Experts)とは: モデル全体の巨大なパラメータのうち、推論時には一部のパラメータのみを「活性化」する仕組みです。例えば397Bモデルでも推論時は17Bしか使わないため、計算コストを大幅に削減できます。
ローカル実行の目安(RAM/VRAM)
| モデル | 必要メモリ目安 |
|---|---|
| 0.8B | 2GB以上 |
| 2B | 4GB以上 |
| 4B | 6GB以上 |
| 9B | 8〜16GB(推奨16GB) |
| 27B | 16〜32GB |
4. Ollamaのインストール方法
macOS
必要OS: macOS 14 Sonoma 以降
- https://ollama.com/download/mac からDMGファイルをダウンロード
- DMGをマウントし、Ollamaアプリを
Applicationsフォルダにドラッグ&ドロップ - アプリを起動するとメニューバーにアイコンが表示される
Versionの確認方法
アプリケーションからターミナルをクリックします

以下のコマンドを実行してバージョンが表示されれば正しくインストールされています
# インストール確認
ollama --version
Windows
必要OS: Windows 10 以降
- https://ollama.com/download からEXEインストーラーをダウンロード
- ダウンロードした
.exeファイルをダブルクリックして「install」ボタンをクリック
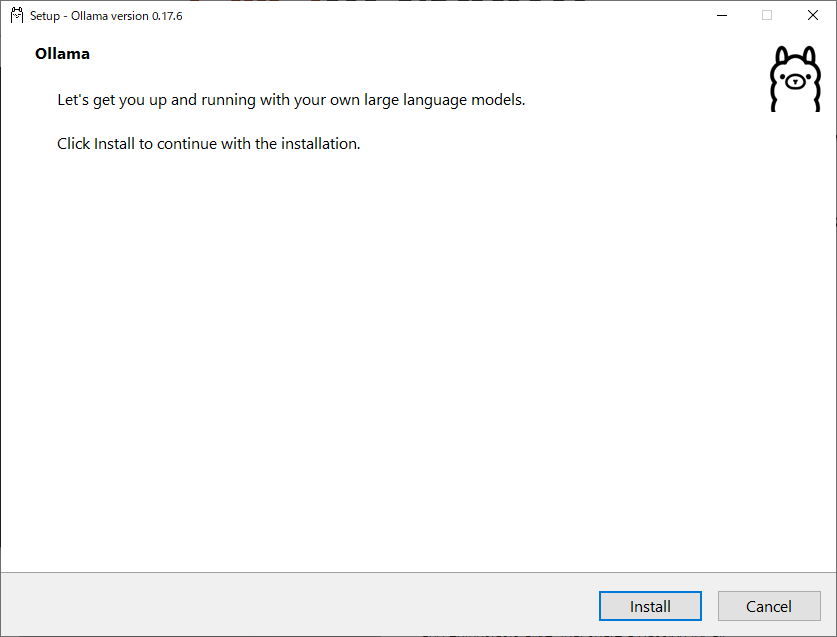
- 画面の指示に従いインストールを完了
- スタートメニューからOllamaを起動
Version確認方法
以下のコマンドを実行するとOllamaのバージョンが確認できます
ollama --version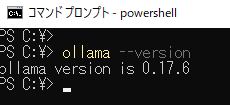
Linux
ターミナルで以下の1コマンドを実行するだけです:
curl -fsSL https://ollama.com/install.sh | shLinuxにインストールすると、ollama.service というsystemdサービスが自動作成され、OS起動時に自動的にOllamaが起動します。
# サービスの状態確認
sudo systemctl status ollama
# サービスの手動起動
sudo systemctl start ollama
# インストール確認
ollama --version5. Qwen3.5のインストールと起動
Ollamaをインストールしたら、以下のコマンドでQwen3.5を利用できます。
モデルの取得と実行(ollama run)
ollama run コマンドはモデルが未取得の場合は自動的にダウンロードし、そのままチャットを開始します。
# 9Bモデルを起動(推奨:一般的なPC向け)
ollama run qwen3.5:9b
# 4Bモデルを起動(軽量版)
ollama run qwen3.5:4b
# 2Bモデルを起動(超軽量版)
ollama run qwen3.5:2b
# 0.8Bモデルを起動(最小版)
ollama run qwen3.5:0.8b
# タグ指定なし(デフォルト最新版)
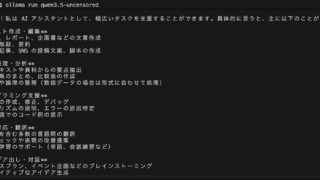
ollama run qwen3.5チャット画面が起動したら、プロンプトに質問を入力して Enter で送信できます。終了するには /bye と入力します。
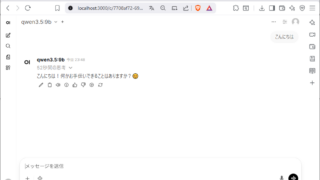
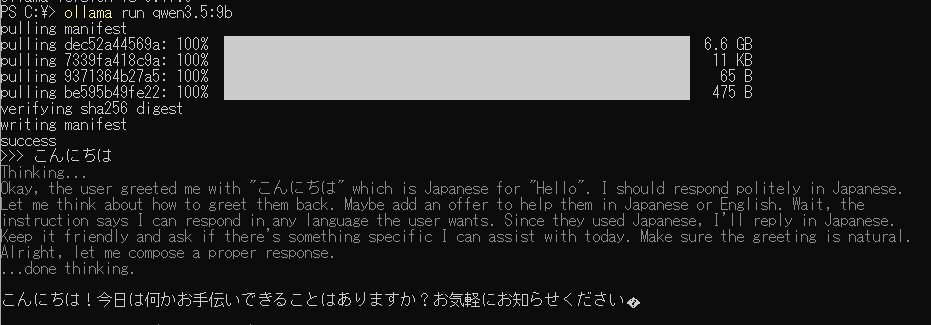
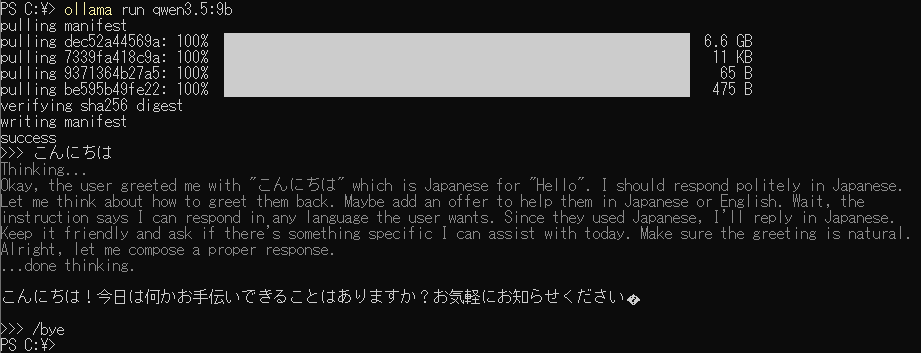
qwen3.5:9bの例
以下はqwen3.5:9bのインストールを実行している状態です

インストールが完了すると「Send a message (/? for help)」と表示されます

「」と表示されている場合、ここにメッセージを入力することができます
以下は「こんにちは」と入力した例です
「」と入力して「」キーを押すとOllamaが終了します
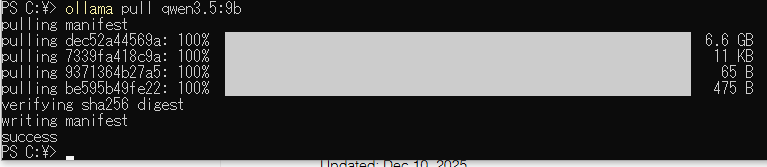
モデルのダウンロードのみ(ollama pull)
runはモデルを実行するコマンドでモデルがダウンロードされていない場合、ダウンロードを同時に実行するコマンドでした。
モデルだけダウンロードしたい場合は以下のコマンドを実行するとモデルだけダウンロードできます
# モデルを事前ダウンロードしておく
ollama pull qwen3.5:9b以下はコマンドの実行です
モデル一覧の確認
ダウンロードしたモデルは以下のコマンドを実行すると表示できます
# ダウンロード済みモデルを一覧表示
ollama list以下はコマンドの実行です

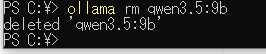
モデルの削除
モデルの容量が多いため不要なモデルは以下のコマンドで削除することができます
# 不要なモデルを削除してストレージを解放
ollama rm qwen3.5:9b以下はコマンドの実行です
6. OllamaのGUI(Open WebUI)の使い方
Ollamaはコマンドライン操作が基本ですが、Open WebUIを使えばChatGPTのようなブラウザUIでAIと対話できます。
Open WebUIとは
Open WebUIはOllamaのフロントエンドとして設計されたオープンソースのWebアプリケーションです。ChatGPT風のインターフェースでローカルAIを快適に利用できます。
主な機能:
- チャット形式での対話
- 複数モデルの同時比較
- 画像入力(マルチモーダル)
- Web検索との連携
- RAG(文書検索拡張生成)
- カスタムプロンプト管理
インストール方法(Docker使用)
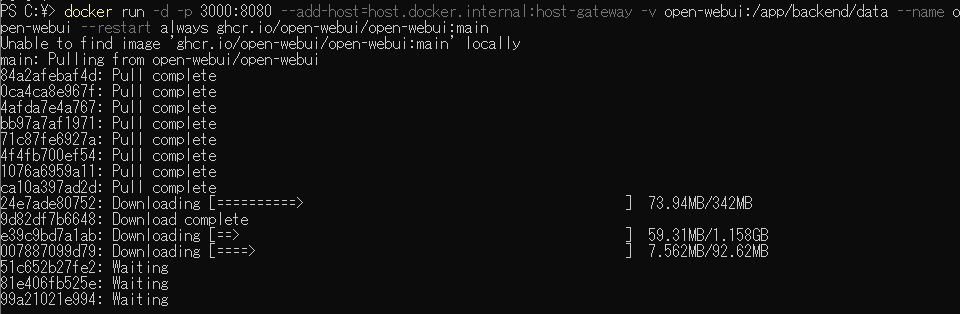
Dockerがインストールされた環境で以下を実行します:
# GPU(NVIDIA)ありの場合
docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda
# CPUのみ(GPU不要)の場合
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:mainDockerがインストールされていない場合は、Dockerをインストールしてください。
Windows

Mac

Linux
起動後、ブラウザで http://localhost:3000 にアクセスします。
基本的な使い方
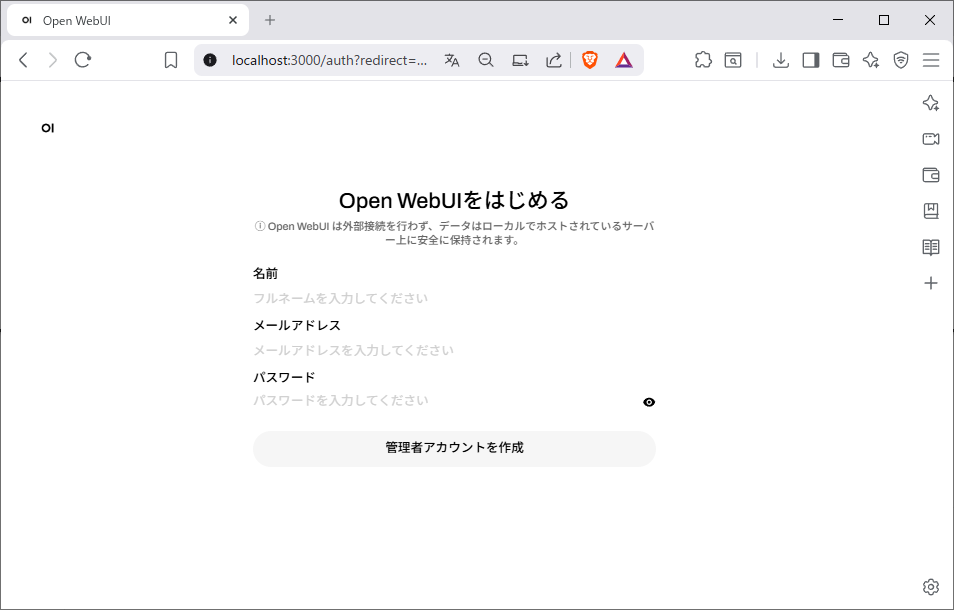
1. チャットを始める
- ブラウザで
http://localhost:3000を開く - 管理者用のアカウントを作成します
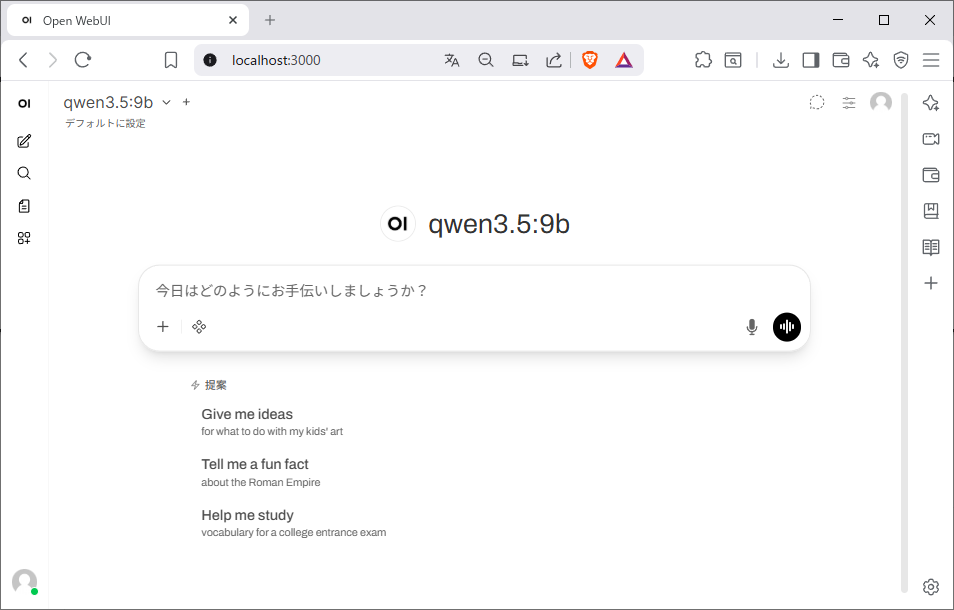
3. チャット画面が表示され、メッセージを送信をできるようになります
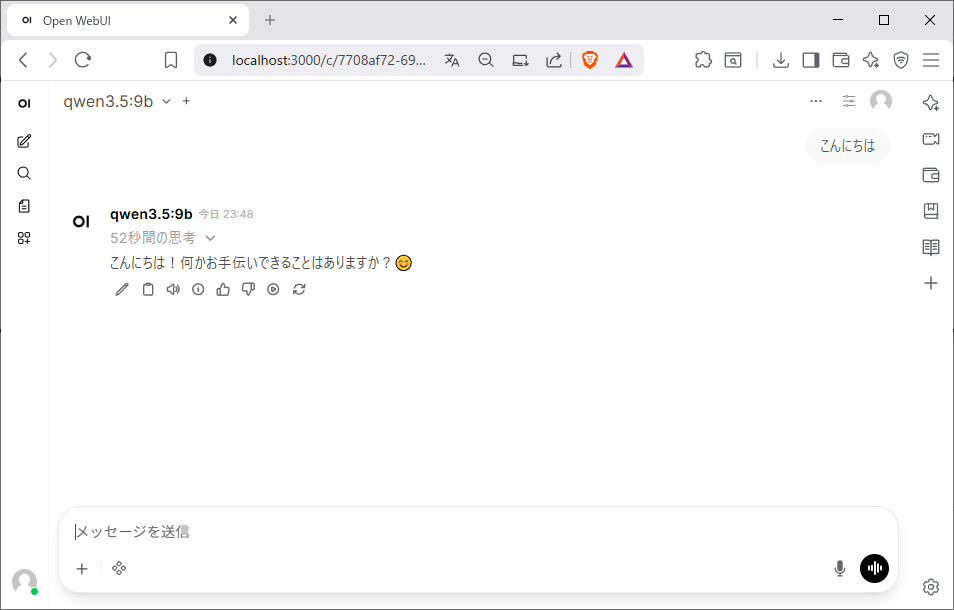
メッセージを送信した例です
2. モデルの管理
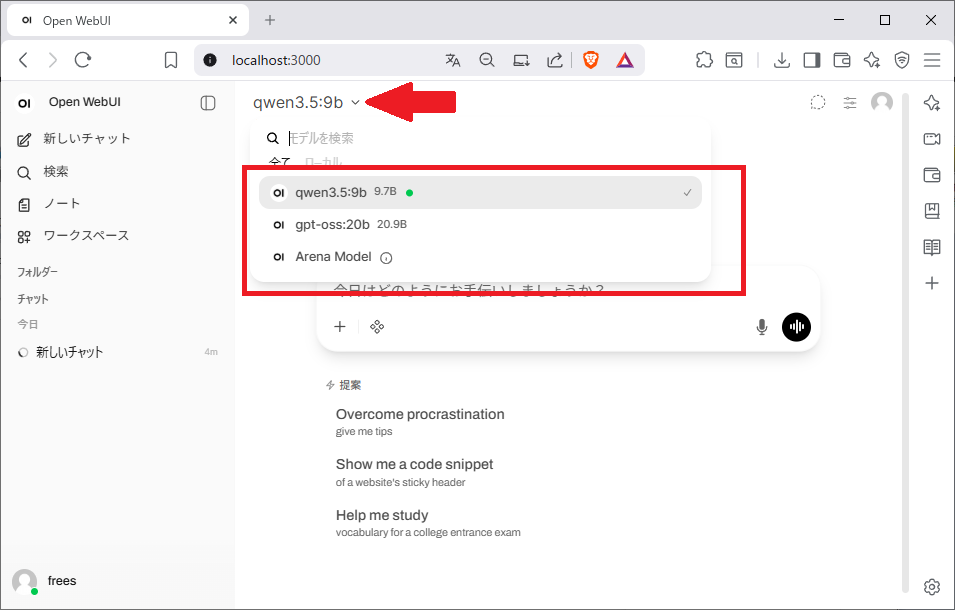
Ollamaのダウンロードしたモデルの切り替えは以下の画面から切り替えることができます
3. 複数モデルの比較
チャット画面 → モデル選択欄の「+」ボタンをクリック → 追加モデルを選択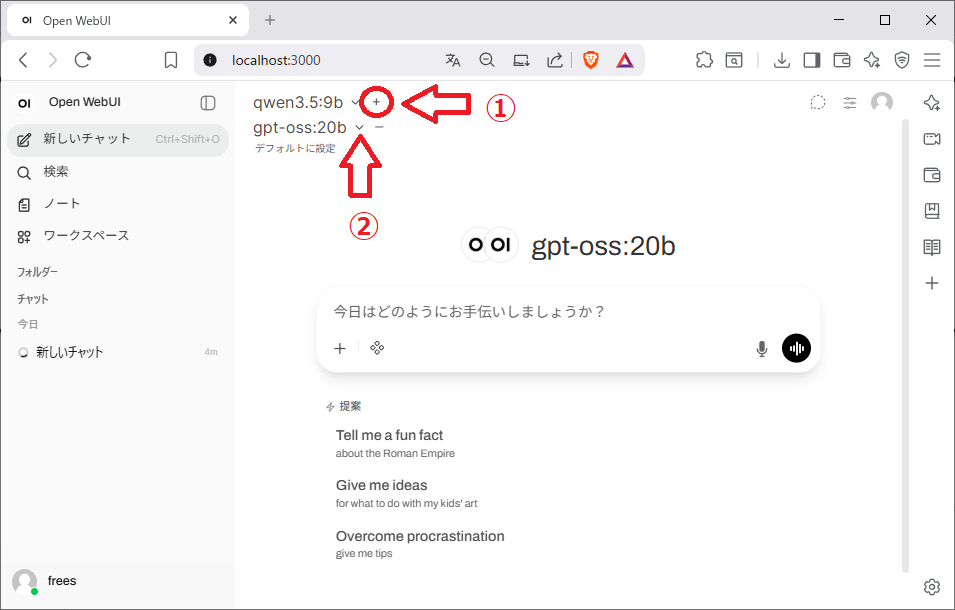
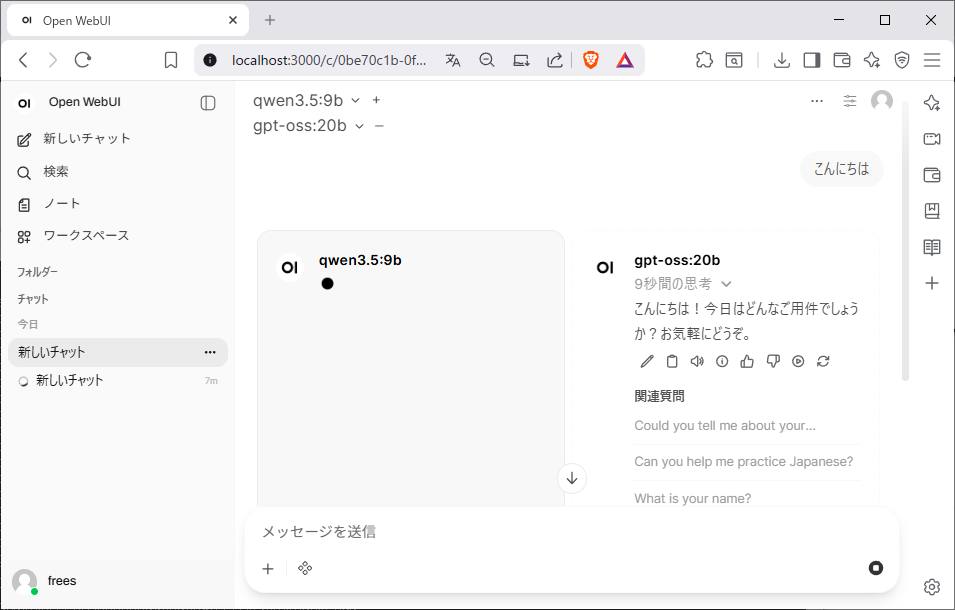
同じプロンプトに対して複数モデルの回答を並べて比較できます。
4. Web検索との連携
- 管理者パネル→ 設定 → ウェブ検索 を有効化
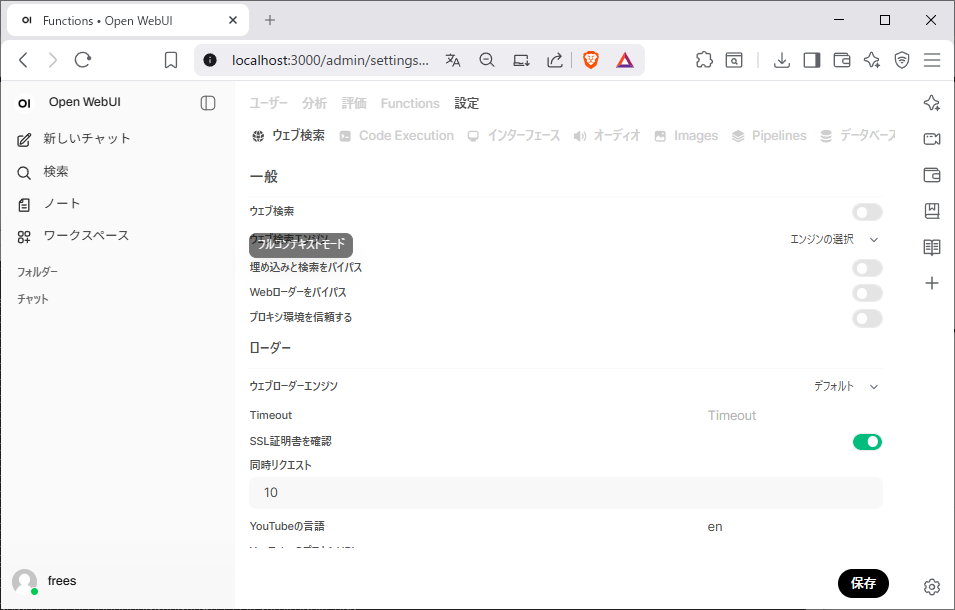
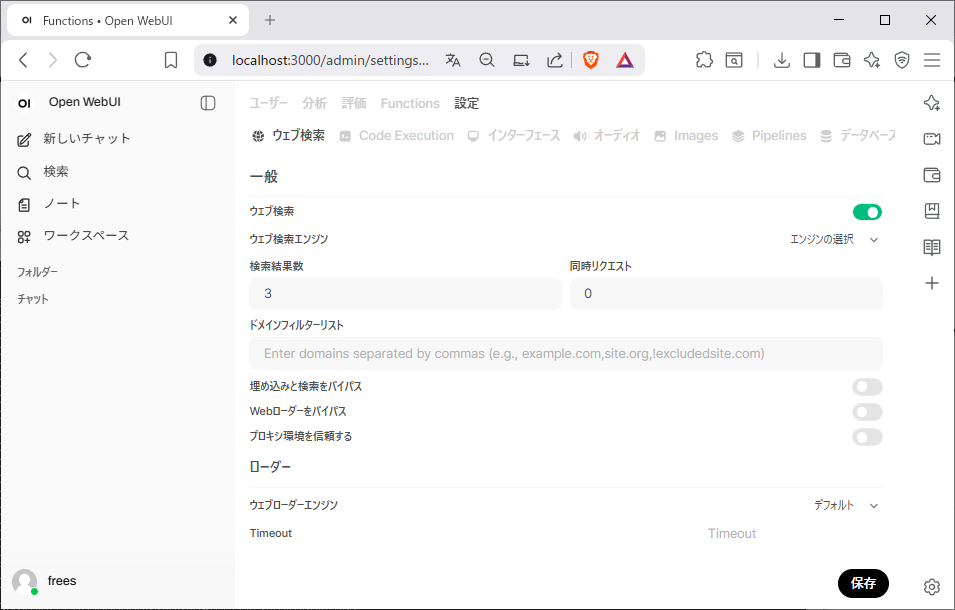
検索プロバイダーに Ollamaを選択APIキーを入れます
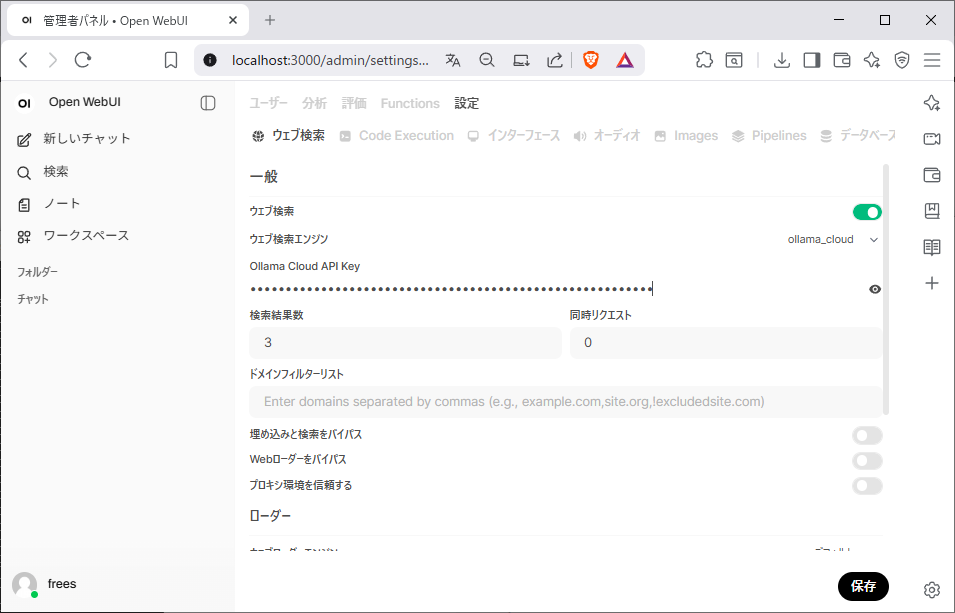
管理者パネル → 設定→ モデル
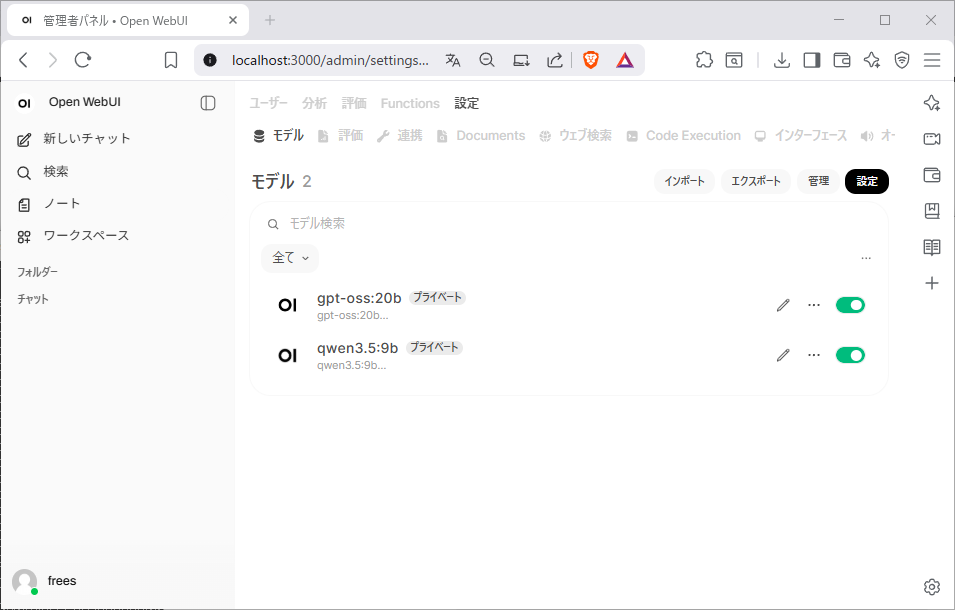
対象モデルを選択 → ウェブ検索にチェックを入れる
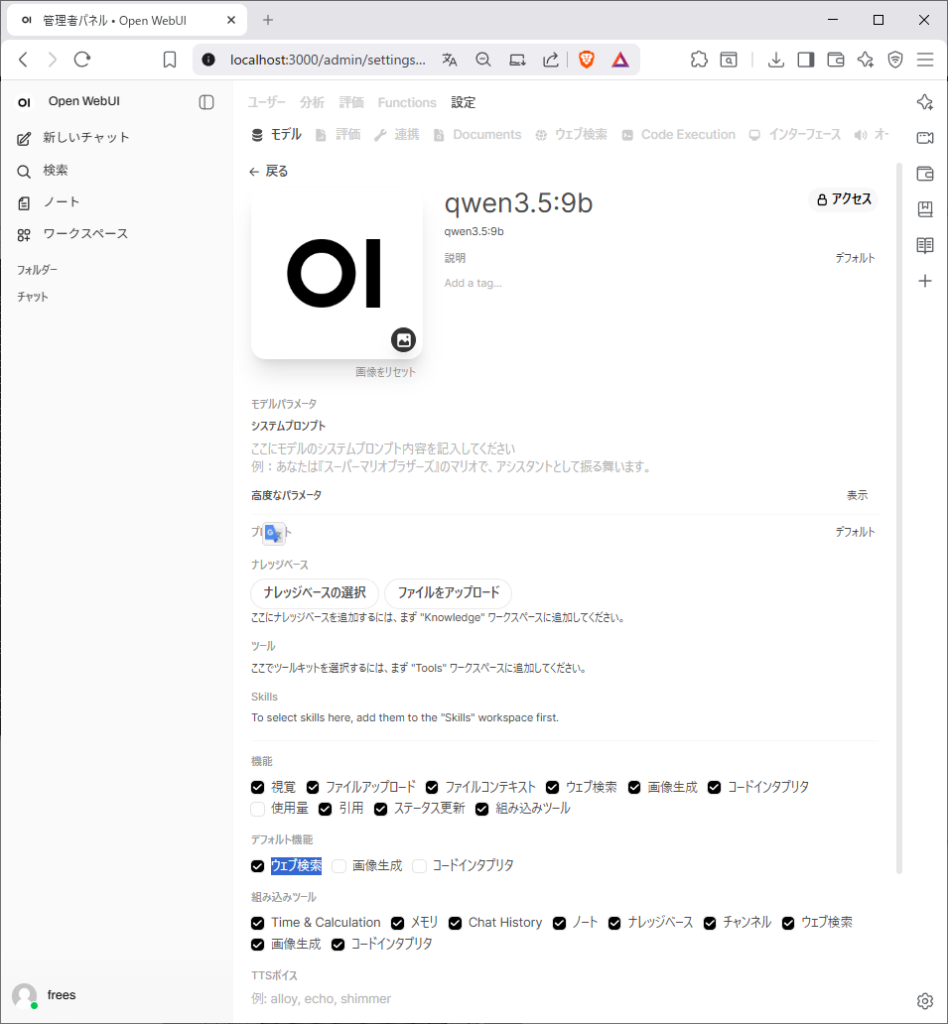
チャット画面に「Web Search」ボタンが表示される
ボタンをオンにして質問するとWebで最新情報も参照しながら回答します
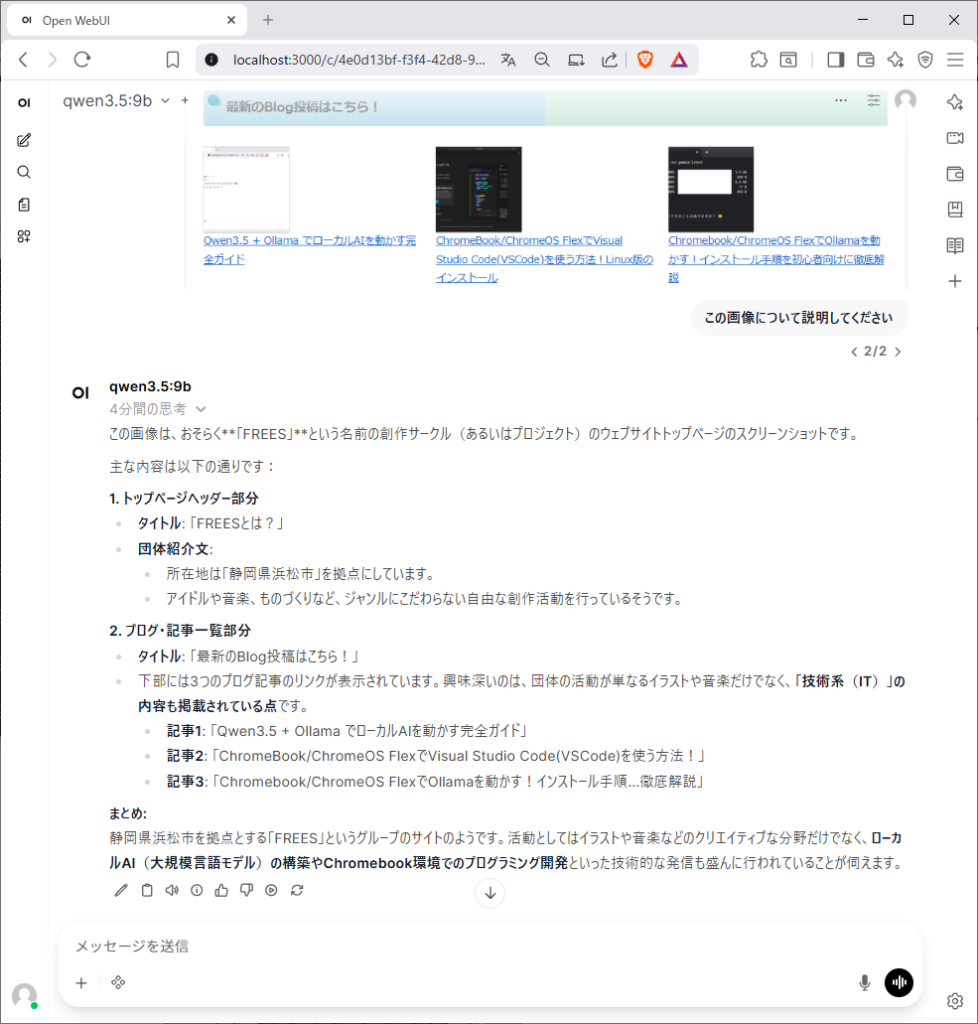
5. 画像の分析
Qwen3.5はビジョン(画像理解)機能を持っています。
- チャット入力欄のクリップアイコンから画像をアップロード
2. 「」などのメッセージを送信
3. モデルが画像の内容を分析して回答
今回はFREESのトップページの画像を連携しましたが、画像について適切な回答をしています
まとめ
| 項目 | 内容 |
|---|---|
| Qwen3.5 | Alibaba CloudのオープンソースLLM、0.8B〜397Bまでの豊富なラインナップ |
| Ollama | ローカルでLLMを動かすツール。簡単操作だがセキュリティ設定に注意 |
| ローカル実行 | ollama run qwen3.5:9b 1コマンドで開始 |
| GUI | Open WebUIでChatGPT風のブラウザ操作が可能 |
Qwen3.5とOllamaを組み合わせることで、無料・プライベート・オフラインで高性能なAIアシスタントを手元に構築できます。スモールシリーズ(0.8B〜9B)は一般的なPCでも動作するため、まずは qwen3.5:4b や qwen3.5:9b から試してみることをおすすめします。

コメント