






Qwen3.6は、Alibaba CloudのQwenチームが2026年にリリースした大規模言語モデル(LLM)シリーズです。なかでも27Bモデルには、推論速度を大きく引き上げる MTP(Multi-Token Prediction) に対応したビルドが用意されており、Ollamaを使えばローカル環境で手軽に動かすことができます。
本記事では、MTPとは何かという技術的な背景から、Ollamaでのインストール、MTP対応ビルドである qwen3.6:27b-mtp-q4_K を起動して動作を確認し、通常版の _Mqwen3.6:27b と生成速度を比較するところまでを順を追って解説します。比較は実際に手元の環境で計測した結果を掲載しています。
Qwen3.6:27b の概要
Qwen3.6:27bは、約270億パラメータの密集(Dense)モデルです。コーディング、数学、長文の読解といった幅広いタスクで高い性能を発揮しつつ、一般的なコンシューマー向けGPUでもローカル実行できる現実的なサイズに収まっている点が特徴です。
Qwen3.6:27bの記事はこちら

| 項目 | 内容 |
|---|---|
| モデル名(通常版) | qwen3.6:27b |
| モデル名(MTP版) | qwen3.6:27b-mtp-q4_K_M |
| パラメータ数 | 約27B(Dense) |
| 量子化 | Q4KM |
| 開発元 | Alibaba Cloud Qwenチーム |
| 主な用途 | コード生成、文章生成、要約、対話 |
| 特記事項 | MTP対応ビルドで推論を高速化 |
MTP(Multi-Token Prediction)とは
MTPは、複数のトークンを同時に予測することで推論(生成)速度を引き上げる、投機的デコーディング(Speculative Decoding)の一種です。
通常のLLMは、トークンを1つ生成するたびに1回の前向き計算(フォワードパス)を行います。これに対してMTPでは、次のように動作します。
- ドラフトとして、これから出力される複数の将来トークンをまとめて予測する
- メインモデルが、その予測されたトークンを 並列に 検証する
- 検証を通過したトークンをそのまま採用し、必要なフォワードパスの回数を削減する
この仕組みにより、出力結果の精度を変えることなく生成だけを高速化できる点がMTPの大きな利点です。Unslothのドキュメントでは、出力の正確性を保ったまま およそ1.4〜2.2倍 の高速化が得られるとされています。
MTPによる高速化の目安
| モデルの種類 | 高速化の目安 |
|---|---|
| Dense(密集)モデル | 約1.4〜2倍 |
| MoE(Mixture of Experts)モデル | 約1.15〜1.25倍 |
Qwen3.6:27bはDenseモデルであるため、MTPの恩恵を比較的大きく受けられるカテゴリに該当します。参考値として、高性能GPU環境ではQwen3.6-27BのMTP版で毎秒160トークン前後の生成速度が報告されています。
メモリ要件に関する注意
MTPはドラフト予測のための追加情報を保持するため、標準のGGUFモデルと比べて おおよそ1GB多くのVRAM/RAM を必要とします。導入前に、利用する環境のメモリに余裕があるかを確認しておくとよいでしょう。
動作環境
Qwen3.6:27b MTPを快適に動かすための目安は次のとおりです。
| 項目 | 推奨 |
|---|---|
| GPU VRAM | 24GB以上だと全レイヤーをGPUに載せやすい |
| システムRAM | 32GB以上(GPUに載りきらない分はRAMで実行) |
| ストレージ | 17GB前後(Q4KM版)+数GBの空き |
| 対応OS | macOS / Windows / Linux |
Q4KM版のモデルサイズは約17GBです。VRAMが少ない環境でも、システムRAMが十分にあればCPU中心で動作します(本記事の計測もVRAM 4GB・RAM 96GBの環境でCPU実行しています)。なお、MTPはドラフト予測のための情報を保持するため、通常のGGUFより おおよそ1GB多くのメモリ を必要とします。

Ollamaのインストール方法
OllamaはmacOS、Windows、Linuxに対応しています。利用環境に合わせてインストールしてください。
macOS
Ollama公式サイト からインストーラーをダウンロードし、画面の指示に従ってインストールします。インストール後、ターミナルで次のコマンドを実行し、バージョンが表示されれば成功です。
ollama --version
Windows
- https://ollama.com/download からEXEインストーラーをダウンロード
- ダウンロードした
.exeファイルをダブルクリックして「install」ボタンをクリック
3. スタートメニューからOllamaを起動

Version確認方法
以下のコマンドを実行するとOllamaのバージョンが確認できます
ollama --version
Linux
次のコマンドを実行すると、インストールスクリプトが自動でセットアップを行います。
curl -fsSL https://ollama.com/install.sh | shQwen3.6:27b MTP の導入と起動
Ollamaの準備ができたら、モデルを取得して起動します。
モデルの取得
まずはMTP対応ビルドをダウンロードします。タグには量子化形式まで含めて qwen3.6:27b-mtp-q4_K_M を指定します。
ollama pull qwen3.6:27b-mtp-q4_K_Mあとで速度を比較するために、通常版も取得しておきます。
ollama pull qwen3.6:27b
モデルの起動
ダウンロードが完了したら、次のコマンドで対話を開始できます。
ollama run qwen3.6:27b-mtp-q4_K_M起動すると入力待ち(Send a message)の状態になります。試しにメッセージを送ってみましょう。

>>> こんにちは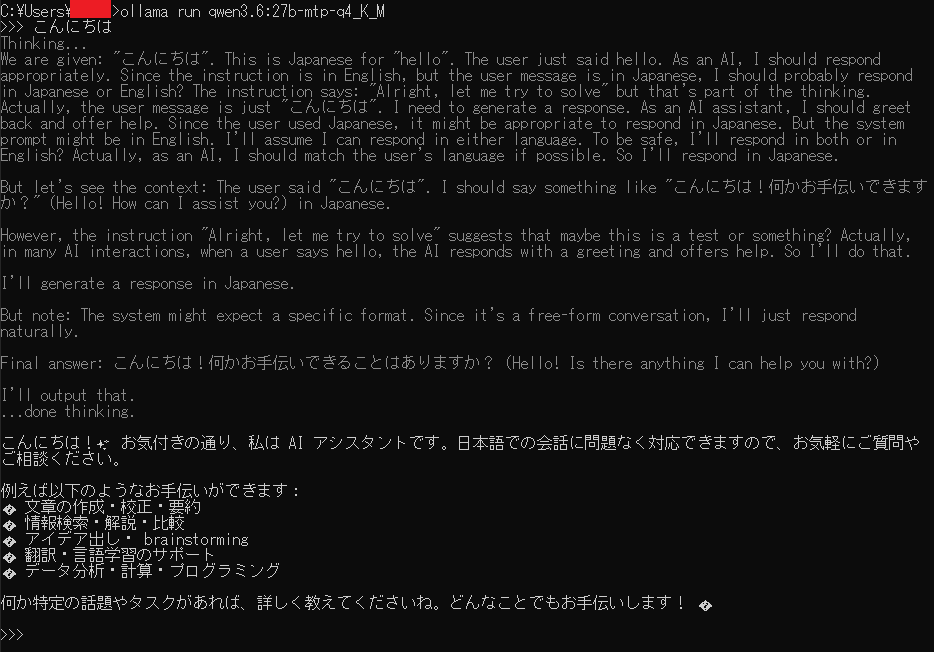
動作確認とベンチマーク(実測)
MTPの効果を確認するには、同じプロンプト・同じパラメータでMTP版と通常版の生成速度(トークン/秒)を比較するのが分かりやすい方法です。手軽に試すなら --verbose を付けて起動し、応答の末尾に表示される eval rate(毎秒のトークン数)を見比べます。
ollama run qwen3.6:27b-mtp-q4_K_M --verbose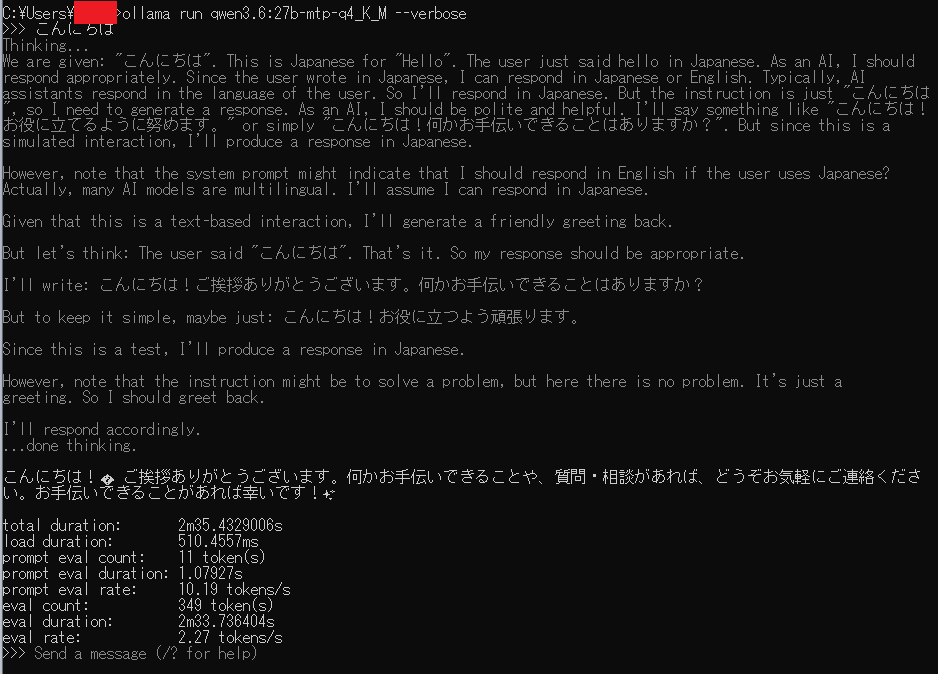
より厳密に比較したい場合は、HTTP APIを使い、シード値と生成トークン数を固定して計測します。次のスクリプトは生成統計(eval と _counteval)からトークン/秒を算出します。_duration
$body = @{
model = "qwen3.6:27b-mtp-q4_K_M"
prompt = "クイックソートのアルゴリズムをPythonで実装し、計算量とともに動作原理を説明してください。"
stream = $false
options = @{ seed = 7; temperature = 0.7; num_predict = 200 }
} | ConvertTo-Json
$r = Invoke-RestMethod -Uri http://localhost:11434/api/generate -Method Post -Body $body -ContentType "application/json"
"{0} tok/s" -f [math]::Round($r.eval_count / ($r.eval_duration / 1e9), 2)model を qwen3.6:27b に差し替えて同じプロンプトを流せば、MTPの有無による差を直接比較できます。
計測環境
| 項目 | 内容 |
|---|---|
| システムRAM | 96GB |
| 実行方式 | CPU中心(VRAMが小さいためGPUオフロードは最小限) |
| 量子化 | Q4KM |
| 生成トークン数 | 200トークン固定 |
計測結果
同一プロンプトを2種類、それぞれシードを固定して計測した結果は次のとおりです。
| プロンプト | qwen3.6:27b(通常版) | qwen3.6:27b-mtp-q4KM(MTP版) | 高速化 |
|---|---|---|---|
| 再帰/ループ実装の説明 | 1.54 tok/s | 2.20 tok/s | 約1.43倍 |
| クイックソートの実装と解説 | 1.56 tok/s | 2.31 tok/s | 約1.48倍 |
今回はほぼCPU実行という条件です。それでもMTP版は通常版に対して 約1.4〜1.5倍 の生成速度を示しました。これはUnslothが示すDenseモデルの高速化の目安(約1.4〜2倍)とよく一致します。GPUに十分なVRAMがある環境では、さらに大きな差が期待できます。
トラブルシューティング:VRAMが小さい環境で起動に失敗する場合
VRAMの小さいGPUでは、Ollamaがモデルの一部をGPUに載せようとした際にメモリ確保へ失敗し、llama-server process has terminated や out-of-memory during startup といったエラーで起動できないことがあります。今回のVRAM 4GBの環境でも、デフォルト設定では起動時にクラッシュしました。
この場合は、GPUへ載せるレイヤー数を0にしてCPU実行に固定すると安定します。APIから指定する場合は options に num_gpu を渡します。
$body = @{
model = "qwen3.6:27b-mtp-q4_K_M"
prompt = "こんにちは"
stream = $false
options = @{ num_gpu = 0 }
} | ConvertTo-Json
Invoke-RestMethod -Uri http://localhost:11434/api/generate -Method Post -Body $body -ContentType "application/json"システムRAMに十分な余裕があれば、CPU実行でも問題なく動作します。GPUを活用したい場合は、載せるレイヤー数を少しずつ増やして、VRAMに収まる範囲を探るとよいでしょう。
まとめ
本記事では、qwen3.6:27b-mtp-q4_K_M をOllamaで動かし、通常版の qwen3.6:27b と生成速度を比較する手順を解説しました。
MTPは複数トークンを先読みして並列に検証する投機的デコーディングであり、出力の精度を保ったまま生成速度を引き上げられる点が大きな魅力です。実際にVRAM 4GBのCPU中心という決して恵まれない環境で計測しても、MTP版は通常版の 約1.4〜1.5倍 の生成速度を記録しました。DenseモデルであるQwen3.6:27bはMTPの恩恵を受けやすく、追加で必要なメモリも約1GB程度に収まります。
ローカルで高速かつ高精度なAIを動かしたい方は、ぜひ qwen3.6:27b-mtp-q4_K_M を試し、手元の環境で通常版との差を計測してみてください。
参考

コメント