






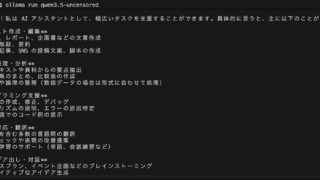
通常のQwen3.5はこちら
本記事では、HauhauCS が公開している検閲なし(Uncensored)の大規模言語モデル Qwen3.5-9B-Uncensored-HauhauCS-Aggressive を、Ollama を使ってローカル環境で動作させる手順を解説します。
「検閲なし(Uncensored)」とは?
通常の大規模言語モデルは、安全性のためにファインチューニングや RLHF(人間のフィードバックによる強化学習)を通じて、特定のトピックや表現に対して回答を拒否する「ガードレール」が組み込まれています。たとえば、法律・医療・倫理的にグレーな話題などに対して「お答えできません」と応答するのがその代表例です。
「検閲なし(Uncensored)」モデルとは、このガードレールを取り除いたモデルを指します。具体的には以下のような特徴があります。
- 拒否応答がない: どのようなプロンプトに対しても回答を試みます
- 能力は損なわれない: ガードレール除去のみを行い、モデル本来の知識・推論能力はそのまま維持されます
- 自己責任での利用が前提: フィルタリングがないため、利用者自身がコンテンツの適切性を判断する必要があります
ローカルで完全にオフライン実行できるため、外部サービスにデータを送らずに扱えるのも特徴です。ただし、生成されたコンテンツの利用は利用者の責任となります。法律や倫理に反する用途での使用は避けてください。
モデル概要
Qwen3.5-9B-Uncensored-HauhauCS-Aggressive は、Alibaba の Qwen3.5-9B をベースに、HauhauCS がすべての拒否応答(refusal)を除去したモデルです。0/465 refusals という結果が示すとおり、能力を損なわずに完全な検閲解除を実現しています。

利用可能な量子化ファイル
GGUF 形式で複数の量子化バリアントが提供されています。VRAM / RAM に合わせて選択してください。
| ファイル名 | 量子化 | サイズ |
|---|---|---|
| Qwen3.5-9B-Uncensored-HauhauCS-Aggressive-BF16.gguf | BF16 | 17 GB |
| Qwen3.5-9B-Uncensored-HauhauCS-Aggressive-Q8_0.gguf | Q8_0 | 8.9 GB |
| Qwen3.5-9B-Uncensored-HauhauCS-Aggressive-Q6_K.gguf | Q6_K | 6.9 GB |
| Qwen3.5-9B-Uncensored-HauhauCS-Aggressive-Q4KM.gguf | Q4KM | 5.3 GB |
| mmproj-Qwen3.5-9B-Uncensored-HauhauCS-Aggressive-BF16.gguf | Vision encoder | 880 MB |
注意: 画像・動画入力を使用する場合は、メインの GGUF に加えて mmproj-*.gguf(ビジョンエンコーダ)も合わせてダウンロードしてください。
Ollama でのセットアップ手順
Ollamaのインストール
Mac
必要OS: macOS 14 Sonoma 以降
- https://ollama.com/download/mac からDMGファイルをダウンロード
- DMGをマウントし、Ollamaアプリを
フォルダにドラッグ&ドロップ - アプリを起動するとメニューバーにアイコンが表示される
Versionの確認方法
アプリケーションからターミナルをクリックします

以下のコマンドを実行してバージョンが表示されれば正しくインストールされています
# インストール確認
ollama --version
Windows
- https://ollama.com/download からEXEインストーラーをダウンロード
- ダウンロードした
.exeファイルをダブルクリックして「install」ボタンをクリック
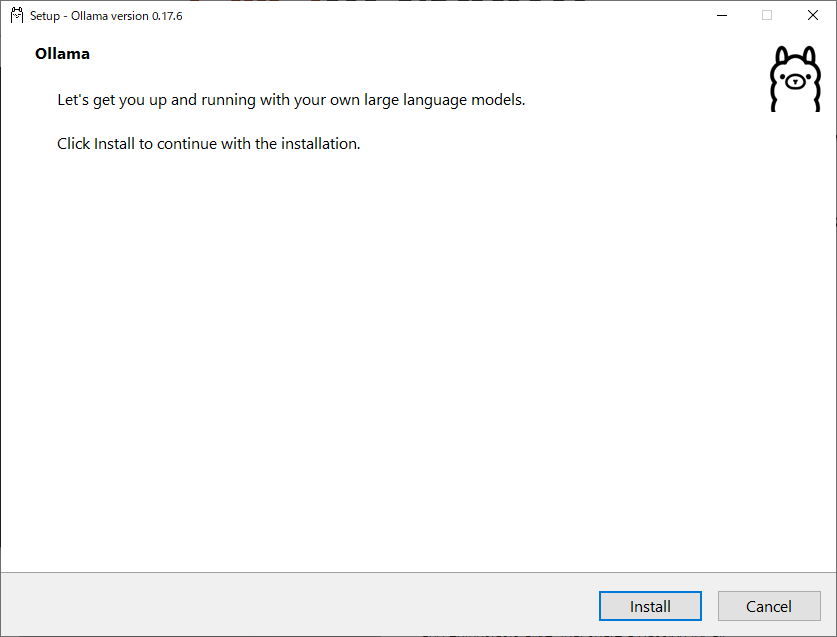
- 画面の指示に従いインストールを完了
- スタートメニューからOllamaを起動
Version確認方法
以下のコマンドを実行するとOllamaのバージョンが確認できます
ollama --version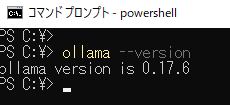
Linux
ターミナルで以下の1コマンドを実行するだけです:
curl -fsSL https://ollama.com/install.sh | shLinuxにインストールすると、ollama.service というsystemdサービスが自動作成され、OS起動時に自動的にOllamaが起動します。
# サービスの状態確認
sudo systemctl status ollama
# サービスの手動起動
sudo systemctl start ollama
# インストール確認
ollama --version2. GGUF ファイルのダウンロード
Hugging Face の HauhauCS リポジトリから GGUF ファイルをダウンロードします。ここでは RAM が 8〜16GB 程度の環境向けに Q8_0(8.9 GB)を使用する例で説明します。
以下のサイトにアクセスします
ダウンロードボタンをクリックするとダウンロードが行えます
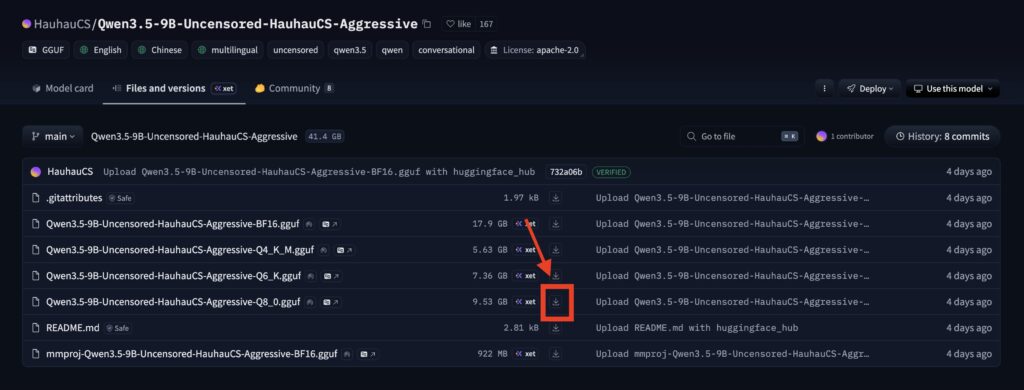
ダウンロードしたものはわかりやすいように特定のフォルダに入れます
3. Modelfile の作成
Ollama は Modelfile を使って GGUF をインポートします。
ダウンロードしたモデルと同じフォルダにを作成します
メモ帳を開き
以下の内容をコピーしてModefileに 貼り付けてください
FROM ./Qwen3.5-9B-Uncensored-HauhauCS-Aggressive-Q8_0.gguf
TEMPLATE {{ .Prompt }}
RENDERER qwen3.5
PARSER qwen3.5
PARAMETER temperature 0.6
PARAMETER top_p 0.95
PARAMETER top_k 20
PARAMETER num_ctx 131072
PARAMETER presence_penalty 1.5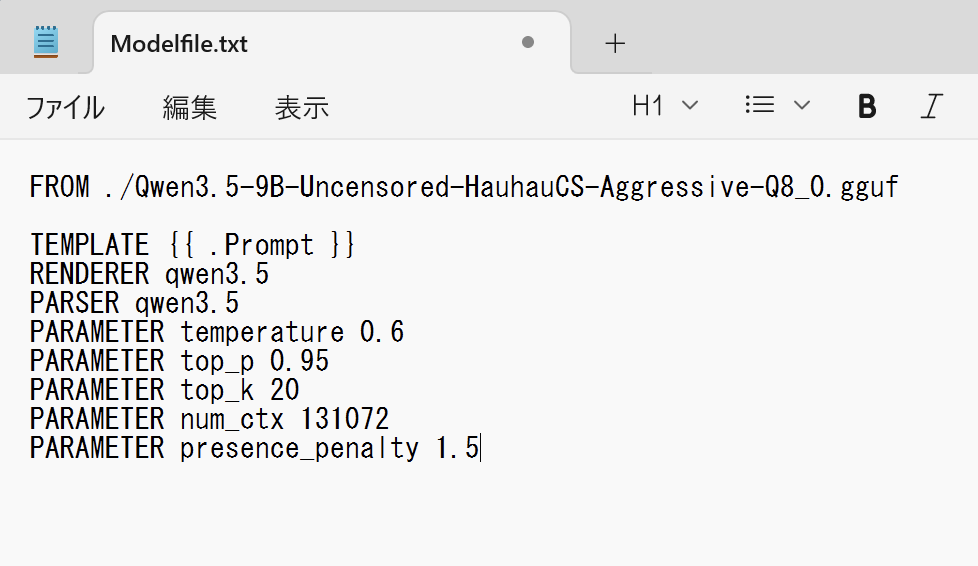
ファイル名を「Modelfile」にして保存します
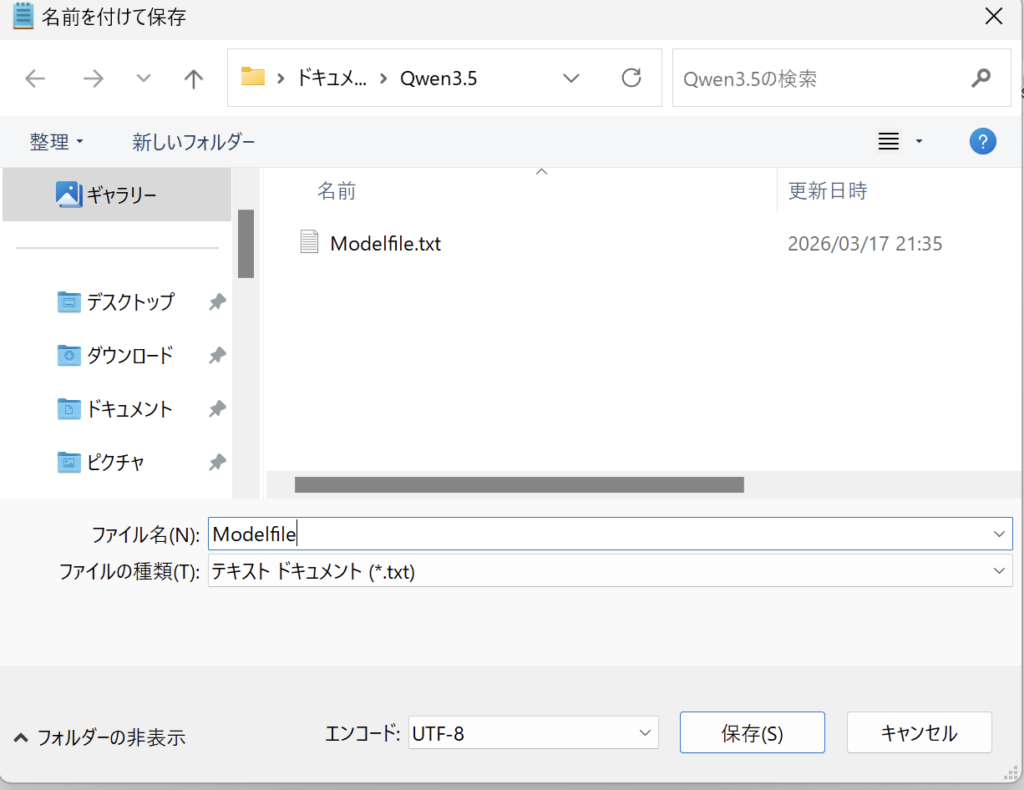
メモ帳では拡張子「.txt」が付いているので名前の変更で「.txt」を消します
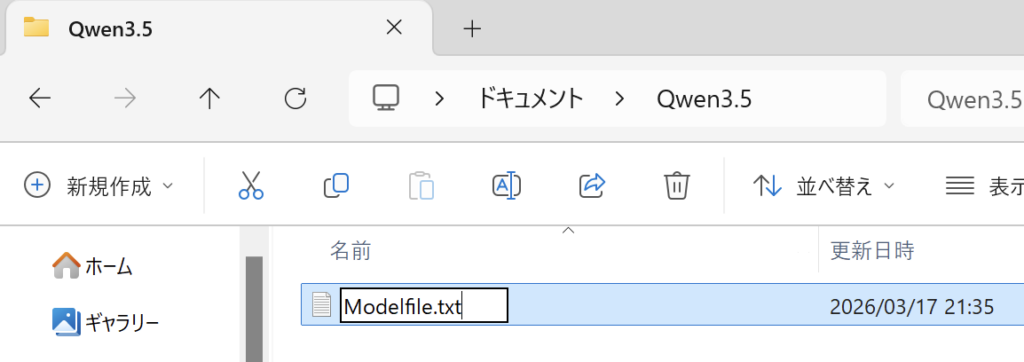
このような感じになれば大丈夫です
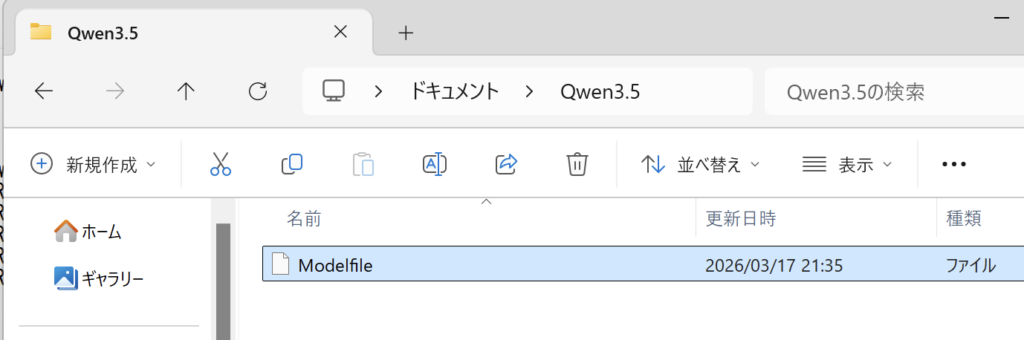
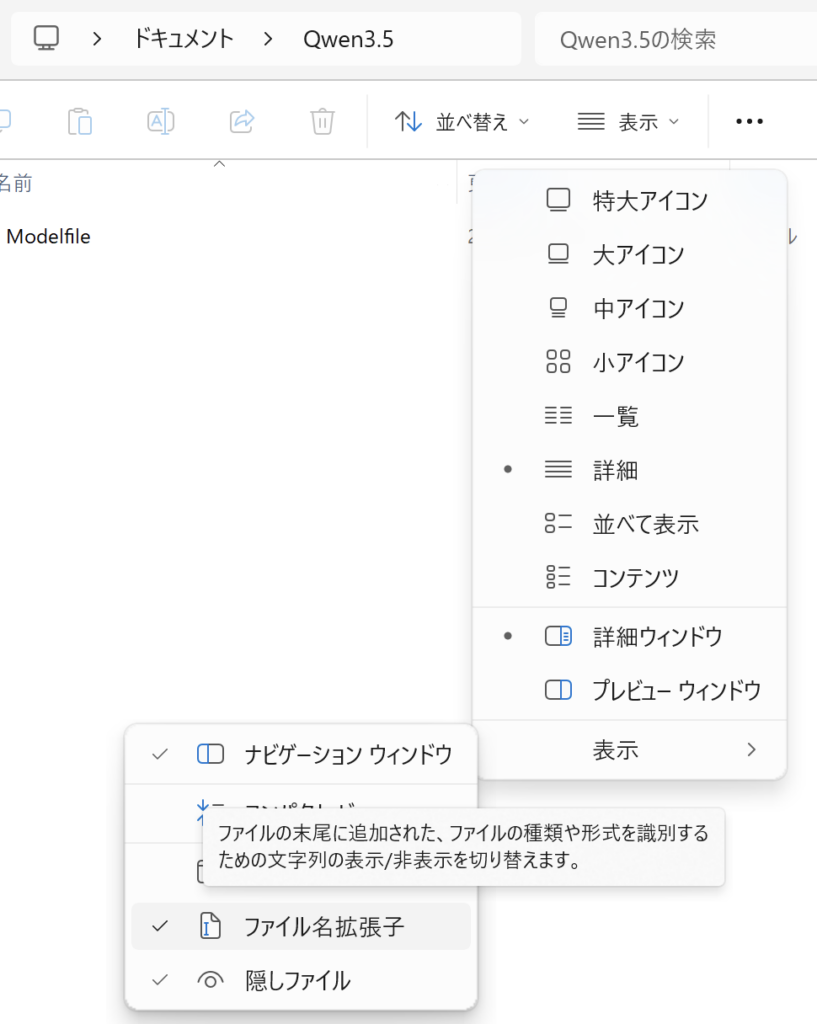
Windowsのエクスプローラでは、「ファイル名拡張子」を有効にしないと拡張子は表示されません
パラメータについて:
temperature=0.6, top_p=0.95, top_k=20: Thinking モード(デフォルト推奨)- Non-thinking モードは
temperature=0.7, top_p=0.8, top_k=20 num_ctx: 最低 128K(131072)を確保することで Thinking 機能が正常動作します
最終的な構成は以下のようになります
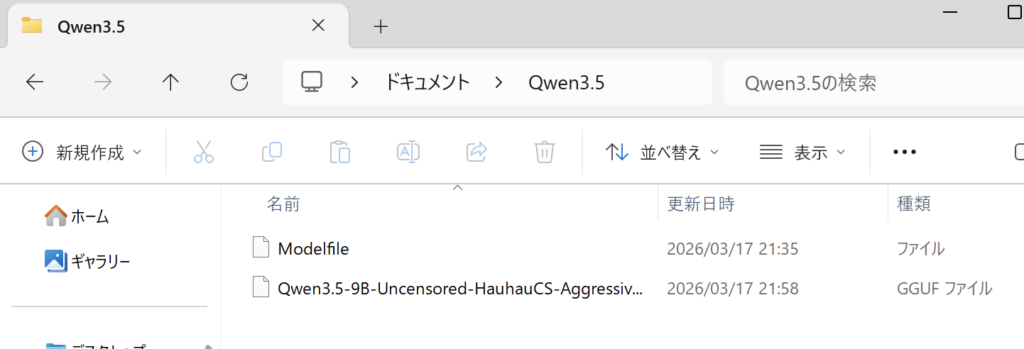
4. モデルの登録
エクスプローラのパスの部分に「cmd」を入力して「」キーを押すとコマンドプロンプトが起動します
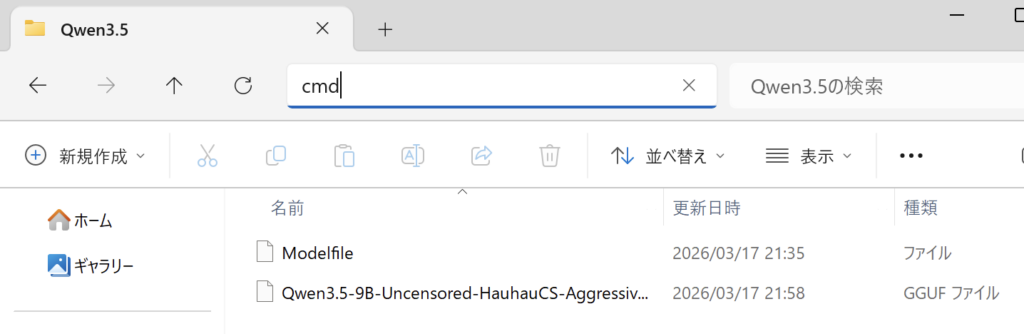
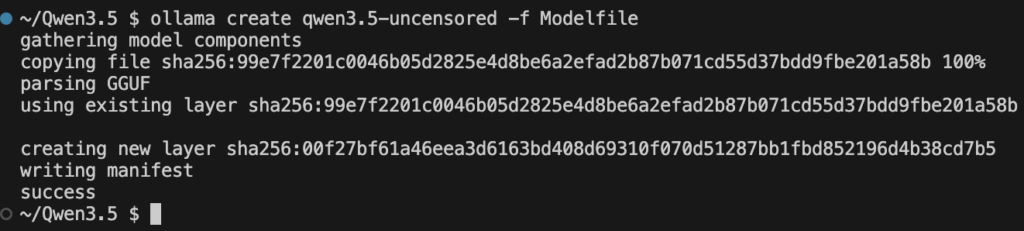
以下のコマンドを実行してモデルの登録をします
ollama create qwen3.5-uncensored -f Modelfileインポートが完了すると以下のように表示されます。
5. モデルの実行
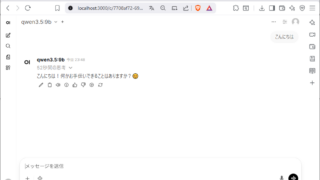
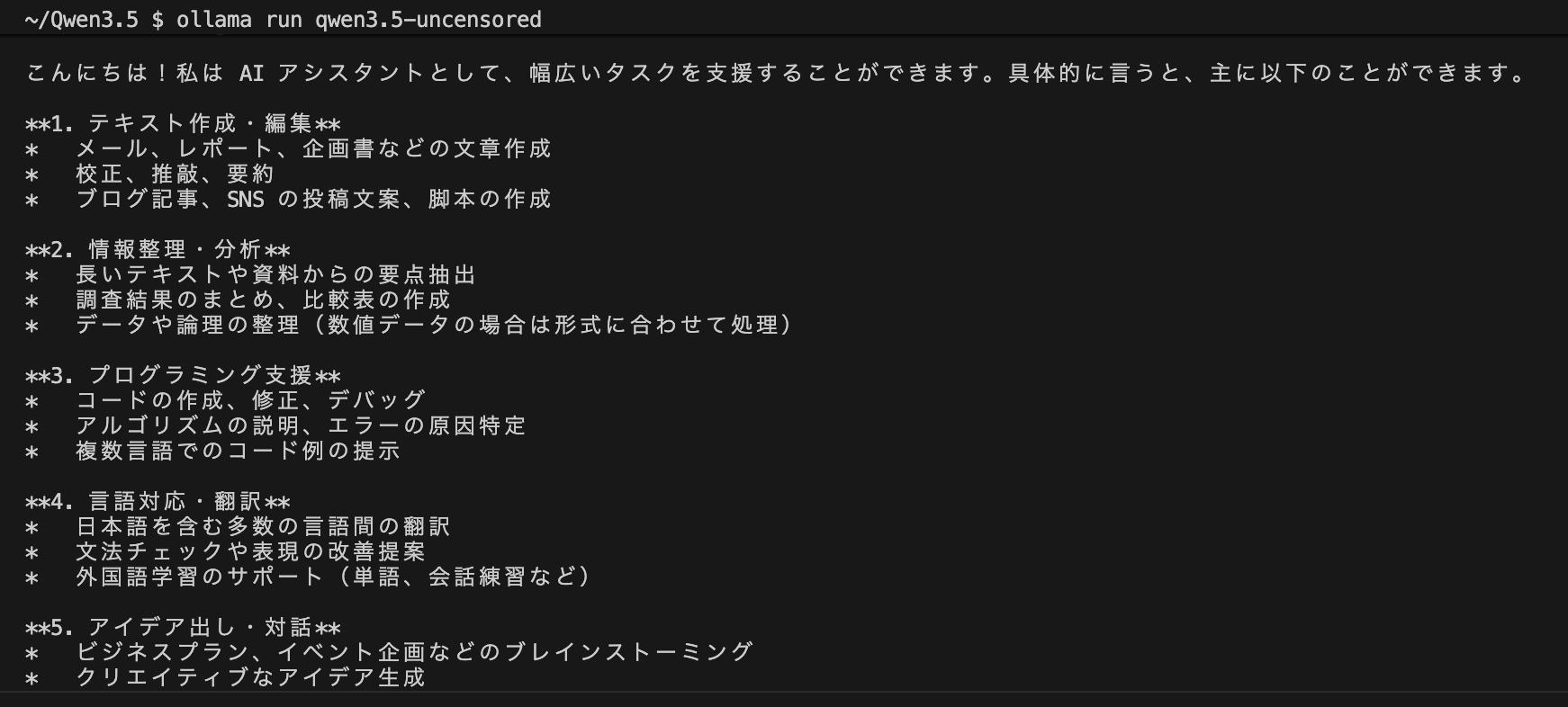
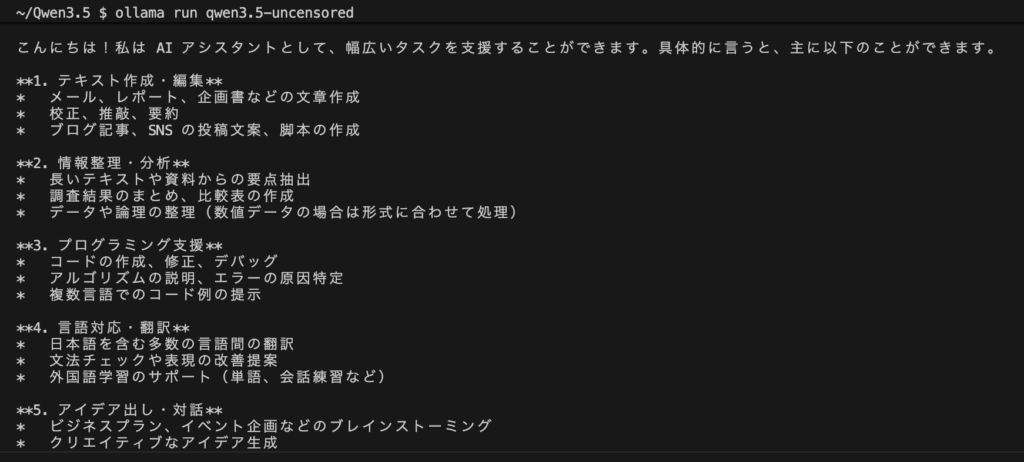
ollama run qwen3.5-uncensoredプロンプトが表示されれば起動成功です。そのまま日本語でも質問できます。

このように回答をしてくれます
6. thinkingの非表示
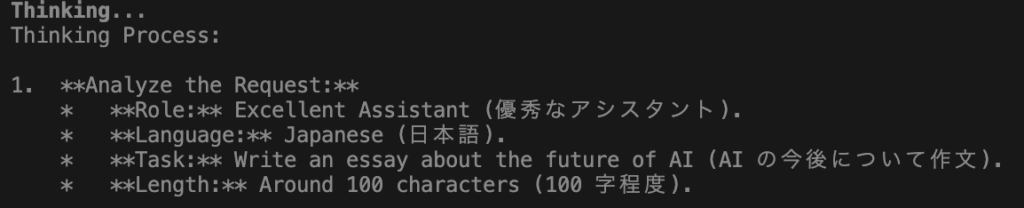
`ollama run`でプロンプトに内容を入れて送信すると以下のように「Thinking」が表示されます
これは、LLMの思考の部分で、思考を何段階に渡り実行をして回答の精度を高めています
これを行うことで、難解な論理問題に強く、ハルシネーション(嘘)が減るとされています。
表示が不要な場合であれば以下のコマンドを実行すると回答だけ表示されます
ollama run qwen3.5-uncensored:latest --hidethinking以下は実行例です。Thinking Processが表示されなくなりました
7. Thinkingモード無効
思考プロセスが長い(表示されるまで時間が長い)などThinkingが不要な場合、以下のコマンドで無効化することができます
/set nothink以下は実際に実行した例です。Thinking Processがないので回答までの時間が短くなっていますが、回答精度が落ちる場合があります

もとに戻すには以下のコマンドを実行します
/set think注意事項
- このモデルは 完全に検閲解除 されており、いかなるプロンプトも拒否しません。利用用途は自己責任で管理してください。
- モデルが応答の末尾に免責事項(例: “This is general information, not legal advice…”)を付加することがありますが、これはベースモデルの学習に起因するものであり、拒否応答ではありません。
- 高スループット・本番環境での利用には vLLM, SGLang, KTransformers の使用が推奨されています。
まとめ
Qwen3.5-9B-Uncensored-HauhauCS-Aggressive は、262K コンテキスト・マルチモーダル対応・201言語サポートという強力なスペックを持ちながら、Ollama を使えばコマンド数行でローカル実行できます。Q4KM 量子化なら 5.3 GB と比較的軽量なので、一般的な開発マシンでも十分に動作します。ぜひ試してみてください。


コメント
初めまして、この記事を読ませていただき
Qwen3.5導入をしようとしたのですが、GGUFのダウンロード後のmodelfileの作り方がわかりません、windowsなのですがpowershellで書き込めばいいのでしょうか?
Modelfileの作り方を追加いたしました。ご確認お願いいたします。
ありがとうございます、モデルが無事実行できました
テキストファイルで作成だったのですね、盲点でした
お手数をおかけいたしました
お手数をおかけいたしました、分かりやすい説明で無事導入できました
ありがとうございます
恐縮ですが、もう一つ質問があり日本語でしつもんして回答の英語の部分を
省略するのは可能でしょうか?
おそらくThinkingの表示だと思いますので、非表示の方法について本ブログで追加いたしました。ご確認お願いいたします。
https://frees.jp/2026/03/08/qwen3-5-9b%ef%bc%88%e6%a4%9c%e9%96%b2%e3%81%aa%e3%81%97%ef%bc%89%e3%82%92%e3%83%ad%e3%83%bc%e3%82%ab%e3%83%ab%e7%92%b0%e5%a2%83%e3%81%a7%e5%8b%95%e3%81%8b%e3%81%99%e5%ae%8c%e5%85%a8%e3%82%ac%e3%82%a4/#toc15
こちらの手順通り進めたのですが
>>> あなたは何が出来ますか?
\n\n何ができるか?と聞かれたら、\n・どんな言葉も読めます\n・どんな言葉も書けます\n・どんな言葉も発音できます\n・どん
な言葉も意味を理解できます\n・どんな言葉も意味を創造できます\n・どんな言葉も他の言葉と組み合わせることができます\n・
どんな言葉も他の言葉に置き換えることができます\n・どんな言葉も他の言葉に分解することができます\n・どんな言葉も他の言
葉に変換することができます\
このように無限ループで入力が終わらないのですが原因わかりますでしょうか・・
「7. Thinkingモード無効」のコマンドを実行しましたでしょうか?
もし実行されましたら一度以下のコマンドを実行してThinkingモード有効にして再度実施していただけますでしょうか?(記事も更新しております)
“`
/set think
“`
ありがとうございます 理解しました
このループで何度も聞き直してることによって精度がいい回答を得られるわけですね そこをちゃんとわかってませんでした
無効にするとちゃんといけました ありがとうございます!