






今回は、ローカルPCで話題のDeepSeeK R1を活用し、AIチャットをブラウザ上で操作できる環境を構築する方法をご紹介します。
現在、AIチャットツールとしてはChatGPTやBirdなどが広く利用されていますが、これらはすべて外部のサーバーを通じて提供されているサービスです。そのため、セキュリティ上の理由から、特に企業や団体内では利用できない場合があります。
そこで、今回はローカルPCや自前のサーバー上でAIチャットを実行できるツールを使い、インターネットに依存せずにAIとやり取りができる環境を作り上げる方法を解説します。これにより、セキュリティの懸念を避けながら、自由にAIチャットを活用できるようになります。
llama.cpp
llama.cppは、大規模言語モデル「LLaMA(Large Language Model Meta AI)」を効率的に動作させるソフトウェアです
C++で実装されています
今回はソースコードからビルドしてみます

下準備
以下のソフトウェアを事前にインストールしてください
- git https://gitforwindows.org/
- git lfs https://git-lfs.com/
- cmake https://cmake.org/download/
CMakeのインストールはこちらを参照してください!

w64devkit
CおよびC++の開発を支援するための軽量な開発キットw64devkitと呼ばれる開発ツールを導入します
以下のURLにアクセスしてw64devkit-2.0.0.zipをダウンロードします
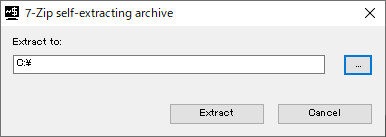
ダウンロードしたら展開をして、「C:\」を指定して「Extract」をクリックしてください
「C:\w64devkit」に展開されます
w64devkitに含まれるdebugbreak.exeがWindows Defenderが脅威として検出される可能性があります。
今回は必要のない実行ファイルのためそのままDefenderで削除されたまま使用します
w64devkit起動
w64devkitフォルダ内の`w64devkit.exe`をクリックします
すると以下のような画面が表示されると思います

llama.cpp
以下のコマンドを実行します
git clone https://github.com/ggerganov/llama.cpp.git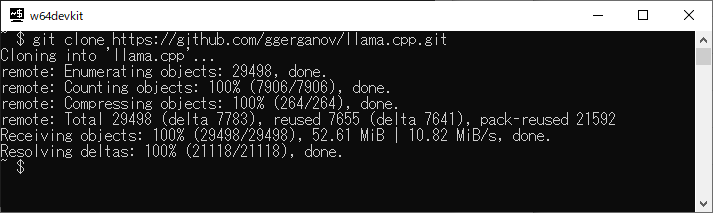
cdコマンドでllama.cppフォルダに移動します
cd llama.cpp/
cmake コマンドを実行します
cmake -B build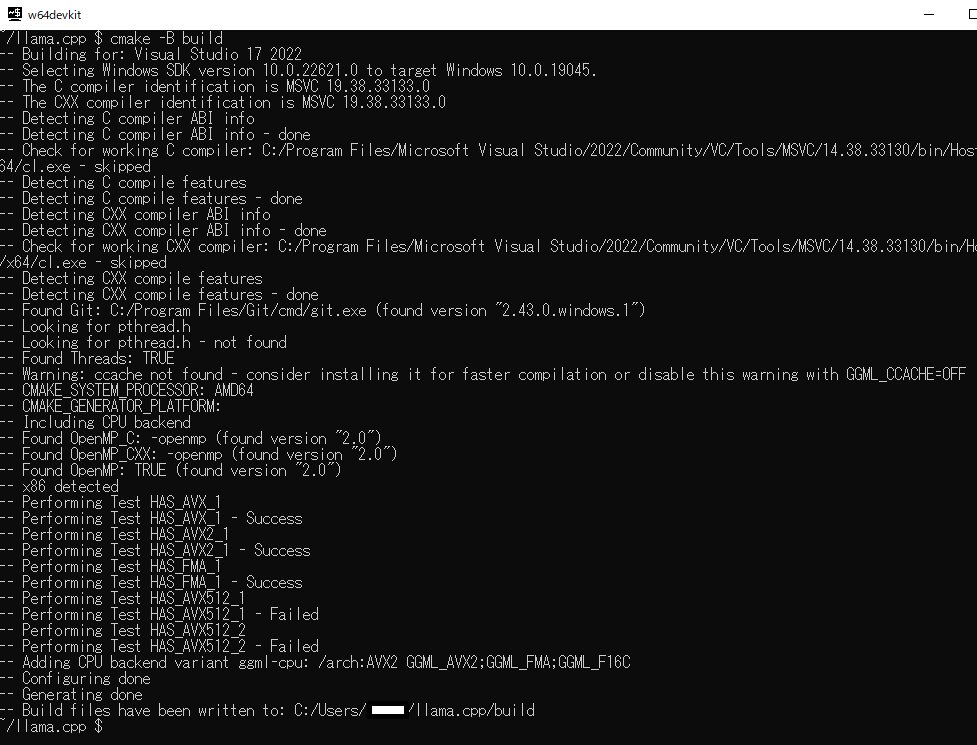
cmakeコマンドでビルドします
cmake --build build --config Release
ビルドが成功すると「build>bin>Release」フォルダにビルドしたバイナリが保存されています
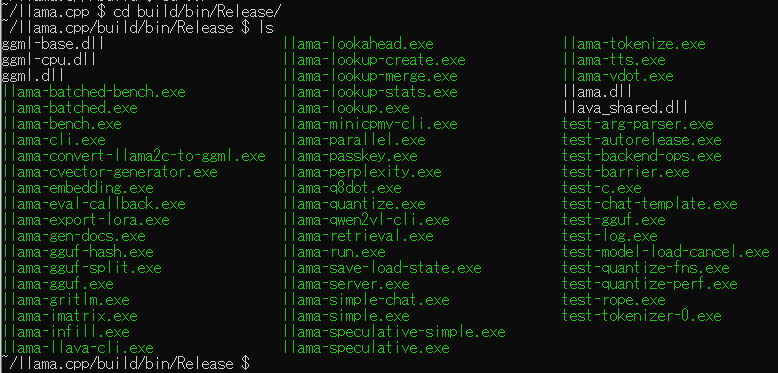
モデル
llama.cppだけでは、動作しません。モデルが必要です。
モデルはさまざまな組織から公開されています。モデルにもいろいろ種類があり、llama.cppでは一般的に「gguf」形式を使用します
今回は今話題のDeepSeek R1をモデルに使用しています
CyberAgentでDeepSeekの日本語チューニングモデルが出ており、

それをllama.cppで動作するgguf形式のものを有志の方が公開しています
14B: https://huggingface.co/bluepen5805/DeepSeek-R1-Distill-Qwen-14B-Japanese-gguf
・DeepSeek-R1-Distill-Qwen-14B-Japanese-Q8_0.gguf:https://huggingface.co/bluepen5805/DeepSeek-R1-Distill-Qwen-14B-Japanese-gguf/resolve/main/DeepSeek-R1-Distill-Qwen-14B-Japanese-Q8_0.gguf?download=true
32B: https://huggingface.co/bluepen5805/DeepSeek-R1-Distill-Qwen-32B-Japanese-gguf
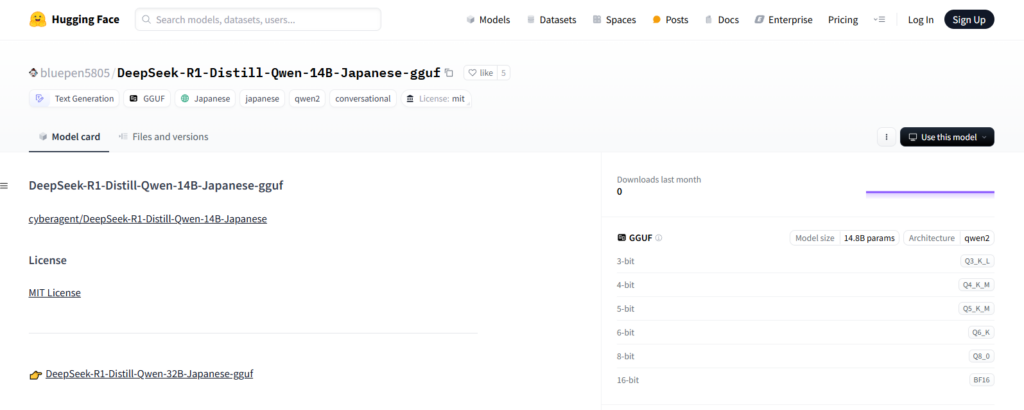
以下のコマンドで直接ダウンロードができます
cd ~/llama.cpp/models/
wget https://huggingface.co/bluepen5805/DeepSeek-R1-Distill-Qwen-14B-Japanese-gguf/resolve/main/DeepSeek-R1-Distill-Qwen-14B-Japanese-Q8_0.ggufダウンロードしたモデルは、llama.cppの「models」フォルダに格納します
実行
以下のコマンドで実行します「-m」のあとは、ダウンロードしたモデルを指定してください。
「DeepSeek-R1-Distill-Qwen-32B-Japanese-Q8_0.gguf」をダウンロードしたら以下のようになると思います
cd ~/llama.cpp/build/bin/Release/
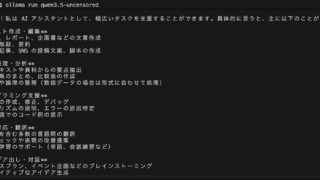
./llama-server.exe -m ../../../models/DeepSeek-R1-Distill-Qwen-14B-Japanese-Q8_0.gguf起動したら、「http://localhost:8080」にブラウザからアクセスしてみましょう
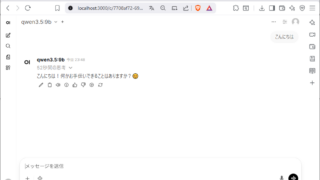
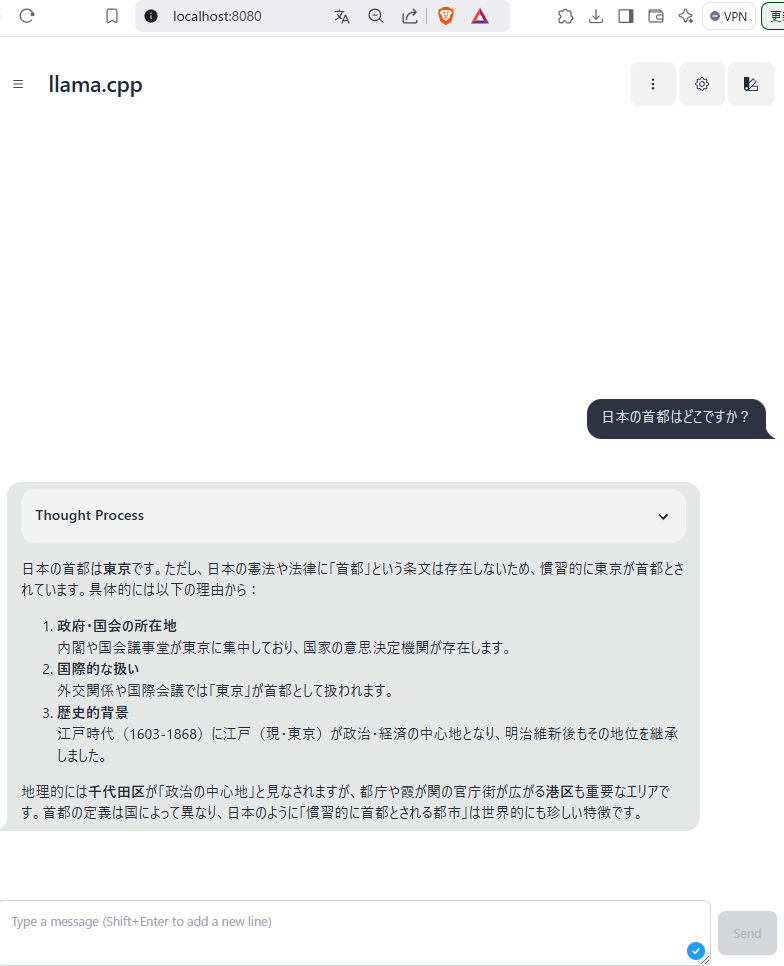
以下の画像のようにプロンプト入力の画面がでたら成功です!
以下の質問は適切に回答されていて性能の高さがうかがえますね!


コメント