







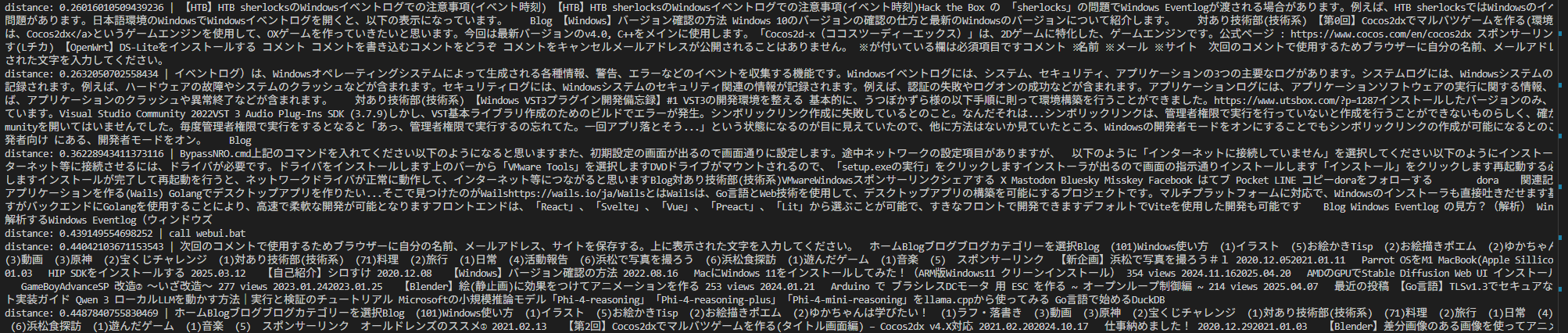
ローカルでいい感じに全文検索を行いたい場合、DuckDBを利用して構築してみる
また、RAGをしたいのでLangChainも触れてみるが今回は、自分のブログサイトの情報をLangChainで取得してDuckDBに入れ全文検索を構築してみる
ソード
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import OpenAIEmbeddings
import torch
import torch.nn.functional as F
import duckdb
from transformers import AutoModel, AutoTokenizer
urls = [
"https://frees.jp/2024/11/16/mac%e3%81%abwindows-11%e3%82%92%e3%82%a4%e3%83%b3%e3%82%b9%e3%83%88%e3%83%bc%e3%83%ab%e3%81%97%e3%81%a6%e3%81%bf%e3%81%9f%ef%bc%81%ef%bc%88arm%e7%89%88windows11-%e3%82%af%e3%83%aa%e3%83%bc%e3%83%b3/",
"https://frees.jp/2024/05/02/amd%e3%81%aegpu%e3%81%a7stable-diffusion-web-ui-%e3%82%a4%e3%83%b3%e3%82%b9%e3%83%88%e3%83%bc%e3%83%ab/",
"https://frees.jp/2023/01/24/gbasp_mod_2/",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=1000,
chunk_overlap=0,
)
doc_splits = text_splitter.split_documents(docs_list)
tokenizer = AutoTokenizer.from_pretrained("pfnet/plamo-embedding-1b", trust_remote_code=True)
model = AutoModel.from_pretrained("pfnet/plamo-embedding-1b", trust_remote_code=True)
device = "cuda" if torch.cuda.is_available() else "cpu"
model = model.to(device)
conn = duckdb.connect("duckdb.db")
conn.execute("""
CREATE TABLE IF NOT EXISTS documents(
id INTEGER PRIMARY KEY,
content TEXT,
metadata TEXT,
embedding DOUBLE[2048])
""")
for i, doc in enumerate(doc_splits):
with torch.inference_mode():
document_embeddings = model.encode_query(doc.page_content, tokenizer)
conn.execute("INSERT INTO documents(id, content, metadata, embedding) VALUES (?, ?, ?, ?)",[
i, doc.page_content, doc.metadata, document_embeddings.cpu().squeeze().numpy().tolist()])
query = "Windows イベントログ"
with torch.inference_mode():
query_embedding = model.encode_query(query, tokenizer)
result = conn.sql(
"""
SELECT content, array_cosine_distance(embedding, ?::DOUBLE[2048]) as distance
FROM documents
ORDER BY distance
""",
params=[query_embedding.cpu().squeeze().numpy().tolist()],
)
for row in result.fetchall():
print("distance:", row[1], "|", row[0])実行した結果おおよそ検索できています
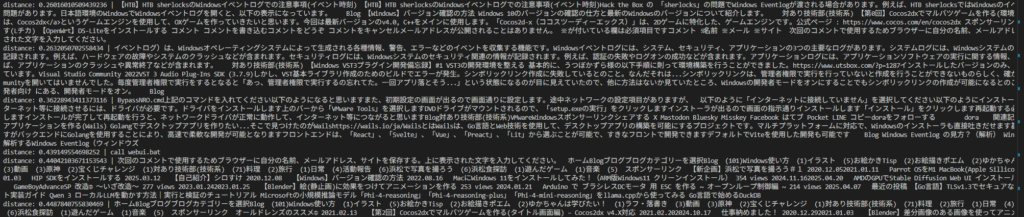
いい感じに直したコード
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
import torch
import duckdb
from transformers import AutoModel, AutoTokenizer
import json
def load_and_process_documents(urls, db_path="duckdb.db"):
conn = duckdb.connect(db_path)
conn.sql("CREATE SEQUENCE IF NOT EXISTS id_sequence START 1;")
conn.execute('''
CREATE TABLE IF NOT EXISTS documents(
id INTEGER DEFAULT nextval('id_sequence'),
content TEXT,
metadata TEXT,
embedding DOUBLE[2048])
''')
tokenizer = AutoTokenizer.from_pretrained("pfnet/plamo-embedding-1b", trust_remote_code=True)
model = AutoModel.from_pretrained("pfnet/plamo-embedding-1b", trust_remote_code=True)
device = "cuda" if torch.cuda.is_available() else "cpu"
model = model.to(device)
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=1000,
chunk_overlap=0,
)
for url in urls:
try:
loader = WebBaseLoader(url)
docs = loader.load()
doc_splits = text_splitter.split_documents(docs)
for i, doc in enumerate(doc_splits):
with torch.inference_mode():
document_embeddings = model.encode_query(doc.page_content, tokenizer)
metadata_json = json.dumps(doc.metadata)
conn.execute("INSERT INTO documents(content, metadata, embedding) VALUES (?, ?, ?)",[
doc.page_content, metadata_json, document_embeddings.cpu().squeeze().numpy().tolist()])
print(f"Processed documents from {url}")
except Exception as e:
print(f"Error loading or processing {url}: {e}")
conn.close()
def search_documents(query, db_path="duckdb.db"):
conn = duckdb.connect(db_path)
tokenizer = AutoTokenizer.from_pretrained("pfnet/plamo-embedding-1b", trust_remote_code=True)
model = AutoModel.from_pretrained("pfnet/plamo-embedding-1b", trust_remote_code=True)
device = "cuda" if torch.cuda.is_available() else "cpu"
model = model.to(device)
with torch.inference_mode():
query_embedding = model.encode_query(query, tokenizer)
result = conn.sql(
"""
SELECT content, array_cosine_distance(embedding, ?::DOUBLE[2048]) as distance
FROM documents
ORDER BY distance
""",
params=[query_embedding.cpu().squeeze().numpy().tolist()],
)
result = result.fetchall()
conn.close()
return result
if __name__ == "__main__":
urls = [
"https://frees.jp/2024/11/16/mac%e3%81%abwindows-11%e3%82%92%e3%82%a4%e3%83%b3%e3%82%b9%e3%83%88%e3%83%bc%e3%83%ab%e3%81%97%e3%81%a6%e3%81%bf%e3%81%9f%ef%bc%88arm%e7%89%88windows11-%e3%82%af%e3%83%aa%e3%83%bc%e3%83%b3/",
"https://frees.jp/2024/05/02/amd%e3%81%aegpu%e3%81%a7stable-diffusion-web-ui-%e3%82%a4%e3%83%b3%e3%82%b9%e3%83%88%e3%83%bc%e3%83%ab/",
"https://frees.jp/2023/01/24/gbasp_mod_2/",
]
#一回実行したらコメントアウトする
#load_and_process_documents(urls)
query = "Windows イベントログ"
search_results = search_documents(query)
for row in search_results:
print("distance:", row[1], "|", row[0])

コメント